|
|
|
|
As it turned out—'twas my first Chord assignment so I had some reading up to do—Rob Watts
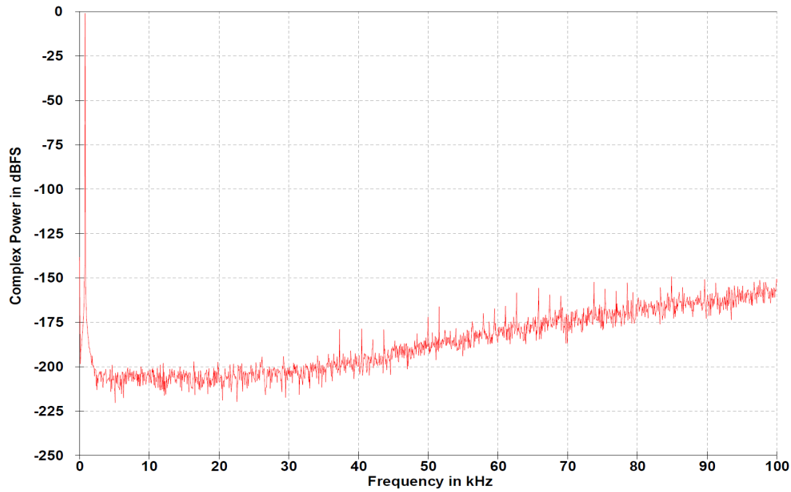
is a designer of analogue and digital chips to consult with actual chip makers. He also invented class Z digital power amp tech, the pulse-array DAC tech and the Watts transient-aligned aka WTA algorithm. Rob works from the assumption that only 10% of what we hear happens in our ears. The rest is signal processing performed by our brain. The graph at right is the final noise-shaping algorithm of the Hugo. Its figures would seem well below the hearing treshold except that when coded to FPGA and compared to a conventional chip's noise shaper, the differences were plain to hear. Our brain's sound processing power is far higher than we think and purportedly ultra sensitive to noise-floor modulation (when noise fluctuates with the music signal). Enter the TT's battery power supply augmented by super caps* to drive down its impact on any noise seen by the DAC; quad-layer ground planes on the PCB; galvanic isolation; and a 3-stage 2048FS filter.
As Rob explained,
the inter-aural-delay neural network of our brain measures time delays between our ears. It operates at ~4µs for a biological 250kHz sample rate. That's far in excess of Redbook's own 22µs timing. Rob's contention is that a FIR filter akin to our brain's processing power would require 1'000'000 filter taps. That's still beyond current tech. But Hugo's WTA filter already uses 26'368 taps which rely on 16 paralleled 208MHz
DSP cores. Hence Chord's refusal to work with commercial chips. Their 150-250 taps are far too low-rent to keep up with the bio DSP of our human brains. Geezus. I'll wear an Intel inside sticker on my forehead now.
|
|
|
| ______________________________________________________________________________________________________________________________________________________ |
* For those wondering why a stationary deck would still use battery power instead of a heavily regulated traditional supply, "the reason the TT uses batteries was for guaranteed noise isolation from the mains supply. The TT project started in Feb 2014. At that time we were not sure how much of the Hugo magic was down to the batteries. So the decision was made to go for the guaranteed low-risk approach and use the batteries. The 2Qute program started much later. Only a few weeks ago did I confirm that we can get battery-quality sound by using lot more RF filtering and regulation. So if TT were designed today, I would go for no batteries, having proven that it can be made to sound identical. The TT can give a bit more power than the Hugo due to the beefed-up output stage, bigger batteries and super caps.
|
 |
To recap, the TT and its smaller predecessor focus on transient fidelity aka timing. For that they use a maximum filter-tap approach to interpolate samples. This is meant to get closer to the infinite-tap ideal which Rob Watts believes would be the ultimate approach to render leading-edge precision perfectly. On how me feeling suddenly so smart despite not being Luc Besson's Lucy applied to the TT's volume control, Rob Watts had this:
"You are correct that the volume function is incorporated into the final WTA filter running at 16FS. Take a look at the below block diagram. The volume function is incorporated within the DSP core that runs the WTA filter which is actually 51 bits of internal precision. The problem with digital volume is not the function itself. With the appropriate bit width and noise shaping/dithering strategies, a perfectly transparent distortion-free volume function is possible. The problem occurs in the DAC itself. DACs are not very good at resolving low-level signals accurately. Digitally attenuating the signal puts more stress on the low-level capability of the DAC. Unlike other delta sigma DACs, Hugo uses my pulse-array DAC scheme with noise shapers that run at 2048FS. The combination of pulse array and running at very high speed means that our DAC has thousands of times more resolution than other delta sigma DACs. On measurements, Hugo has no distortion below -30dBFS and can resolve -120dB to an accuracy of 0.01dB (if you wait long enough to take the measurement!). This means that low-level details are resolved more accurately. That is one reason for Hugo's soundstage depth capabilities.
"The benefit of digital volume is transparency since an analogue volume control also has low-level (and some high signal level) distortion issues. Putting more processing power into the digital domain where it can be done completely transparently gives a simpler analogue section. And that results in much better refinement, detail resolution and being able to place instruments in the soundstage far more accurately."
Relative to my assumption that this would imply DSD-to-PCM conversion, Rob affirmed it. "The above is the primary reason why DSD is filtered and converted to PCM. DSD requires complex analogue filters. By putting those in the digital domain, I can do this transparently. Plus of course, volume and crossfeed can only be done with PCM."
|
|
|
|
|
|
 |
Chord's crossfeed circuit reiterates the underlying theme. Provide more data for our brain's own processing power so that it may create a more convincing sonic facsimile for our perception. Headfi listening is peculiar in that it isolates each channel to one specific ear. With loudspeakers, each ear hears both speakers. We do the same with life sound for any source. The arrival-time differential between the ears contains vital data for any sound which our brains need to map a proper soundstage and determine distance and point of origin. That's what crossfeed simulates. It injects/bleeds a predetermined amount of right-channel signal into the left ear and vice versa. This trick expands the sonic bubble inside our head by replacing the hard-panned left, middle and right spot lights into one big flood light. With the TT's formidable computing power on... er, tap, it was a given that Chord would operate their variable crossfeed in the digital domain. We might paraphrase that as, digital smart, analogue dumb. If so, one would give the complicated jobs to digital and reserve the more basic stuff for analog.
|
 |
As a place of work, Chord's historical brick digs by the river strike a most serene and colourful chord indeed.
|
As an introduction to the Hugo TT which wasn't expected to start shipping until the latter part of Q1, this intel had to suffice until a review loaner became available. Until then, all of it remained on the QTT as it were. Except for the seemingly obvious: this looked to be a technological tour-de-force. WIth a currency exchange rate which rendered £2'995 as €4'000, the TT's sticker seemed surprisingly sane when one considers flagship tech competitors from EMM Labs and Playback Design for just two examples. In fact, AURALiC's €3'300 Vega which doesn't do headfi isn't that far off in the other direction. And given the DSD hype, I at least found it most refreshing to see an engineering-driven counter argument in favour of PCM conversion (which incidentally Bel Canto Design echo as well).* To add more spice, John Franks reminded me. I'd as yet never laid ears on the original. To better appreciate its popularity, I really ought to. He'd thus send out a small Hugo. That would wet my feet, then double-team against the TT to report on overlap and differences and speak to those who view the twice-priced TT has far too similar on performance to make any sense. Finally Hadi Özyaşar, our new contributor from Turkey's Andante magazine, would supply a comprehensive 2nd opinion on the TT. F |
| ______________________________________________________________________________________________________________________________________________________ |
* For the technically inclined, here is more on Rob's thinking re: DSD and PCM originally posted to HeadFi.
"First some history. I started getting involved in designing DACs in 1989 when I heard the Phillips Bitstream DAC, the SAA7320. Compared to multi-bit DACs of the time, it was a revelation. Digital was starting to sound smooth and refined. Now these DACs were PDM types—that is, 1 bit with 256 x oversampling—hence technically exactly the same as DSD but running at 256 not 64 times. Now I started with these DACs, made improvements and realised that their noise shapers were limiting resolution. To improve resolution, I started using multiple chips each with their own dither. Noise shapers convert PCM to lower resolution data like 1-bit DSD. I also found that the out-of-band noise from these noise shapers was overloading the analogue sections, giving noise floor modulation to make them sound harder. These DACs also were innately very sensitive to clock jitter. To try to solve these problems, I designed the PDM1024. It had multiple noise shapers to improve resolution and digital filtering (delay and add) to help with the jitter sensitivity and out-of-band noise. The PDM1024 (we're in the early 1990s now) gave a big step forward but I could not resolve all of these problems. So I started developing Pulse Array, a multi-bit noise shape technology. To solve the noise-shaper resolution problems, it runs at 2048 FS and is 5th order or better. This theoretically approaches 90dB more noise shaper resolution than PDM at 256FS; and 150dB more resolution than DSD64. The Pulse Array modulation scheme also has the benefit of much lower master clock jitter sensitivity than native DSD/PDM. More importantly, it has no jitter-induced noise which is signal dependent because it is a constant clocking scheme with no innate noise floor modulation. Also, by running at 2048FS, the noise-shaper noise at 1MHz is much lower – about 1000 x lower than usual DACs. This means a simple analogue single stage with minimal filtering for much more transparency. Also, the analogue active section has a much easier time since RF-induced noise floor modulation is fundamentally easier.
|
 |
"Now this happened in 1995. At the same time, silicon DAC designers were on a similar path, moving performance DACs to multi-level noise shaping away from single bit. At this time DSD started. That was moving in the opposite direction. Instead of 256FS, it had reduced to 64FS simply because of data rate limitations on optical disks. As I talked about in earlier posts, DSD has a major benefit. It does not have the big timing problems of PCM. But it suffers from much poorer resolution and creates more distortion and noise than PCM. Using the WTA filter addresses the timing problems of PCM (I won' say eliminates because I think we need more taps than we have today), giving you the potential of better resolution from PCM and overall better sound. When DSD was first presented, it was claimed that processing could be maintained natively. If you wanted to add volume control or freq EQ, you could modify the bit-stream directly and re-noise-shape the OP. But people quickly found that this was not possible. When you re-noise-shape DSD64, it very quickly degrades in terms of noise performance. You simply cannot connect 3 or 4 noise-shaped stages together unless you want awful performance. With regular PCM this is not the case. You can add many stages together and it won't significantly change measured performance. This is why DSD is initially recorded with PCM at 352.8 kHz aka DXD. Then it can be mixed, EQ etc. with minimal losses. Then finally it gets converted from DXD to DSD. If you can get hold of DXD master recordings and their DSD versions, you can hear the transparency losses of DSD (try the 2L website who have free samples).
"... with Hugo we have a potentially much more serious problem with DSD as we have to do volume control and crossfeed EQ. This means DSD has to be converted to PCM and at the 16FS rate the crossfeed and volume control work at. The filtering was much more challenging now as I had to decimate the signal (make it a smaller sample rate). This meant a new filter design. The Qute filter would have had aliasing problems due to insufficient stop-band rejection. I needed much more than the 50dB filtering of the Qute. So I decided on a sledge hammer approach to aliasing problems by having 140dB of rejection. This actually is much better than pro-standard ADC aliasing filters but that's another story. The other benefit of this filter was that it removed the DSD noise at 100kHz since it had 110dB worth of rejection at that frequency. Now I could have the benefits of PCM with DSD because out-of-band noise was non-existent. This Hugo filter was designed, verified, measured and listened to. And I was worried about the listening tests as I had not decimated DSD before. I listened to the Qute filter directly and compared it to the Hugo decimating filter with no volume or crossfeed, with identical gain on both filters. The Hugo DSD filter sounded very much better. DSD was a lot smoother, warmer and more natural, with no detectable loss in transparency or timing. So the benefits of the much better filtering at 100kHz far outweighed the potential decimation errors by a very big margin."
|
 |
|

|

|
|